


目录
近年来,随着 OpenAI 的 o 系列模型、Claude3.5Sonnet 和 DeepSeek-R1等大型语言模型的快速发展,人工智能的知识和推理能力备受关注。然而,很多用户在实际使用中发现,这些模型有时未能完全按照输入的指令执行,导致输出结果虽然内容不错,却并未满足具体的格式或内容要求。为了深入研究和评估这些模型的指令遵循能力,美团 M17团队推出了全新的评测基准 ——Meeseeks。
Meeseeks 专注于评测大模型的指令遵循能力,采用了一种创新的评测视角。与传统的评测方法不同,Meeseeks 关注的是模型是否严格遵循用户的指令,而不单纯评估回答的知识准确性。这一评测框架将指令遵循能力拆解为三个层次,确保评估的深度与广度,具体包括:任务核心意图的理解、具体约束类型的实现和细粒度规则的遵循。
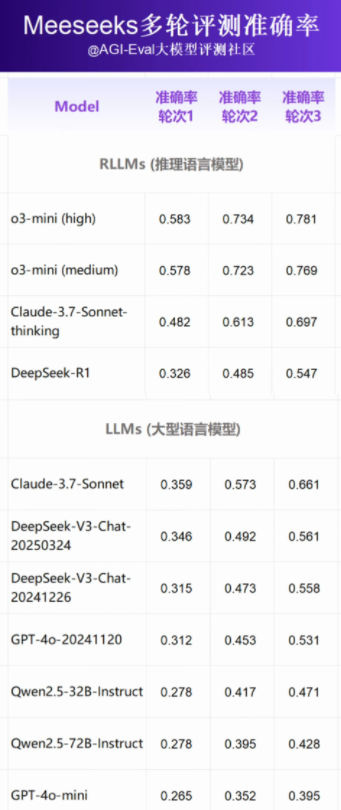
在最近的评测中,基于 Meeseeks 的结果显示,推理模型 o3-mini(high)以绝对优势夺得第一,另一版本 o3-mini(medium)紧随其后,Claude3.7Sonnet 则稳居第三。相比之下,DeepSeek-R1和 GPT-4o 的表现则不尽如人意,排名分别为第七和第八。
Meeseeks 的独特之处在于其广泛的评测覆盖面和高难度的数据设计。此外,它引入了 “多轮纠错” 模式,允许模型在初次回答不符合要求时进行修正。这一模式显著提升了模型的自我纠错能力,尤其是在多轮反馈后,所有参与的模型的指令遵循准确率都有明显提高。
通过 Meeseeks 的评测,研究团队不仅揭示了不同模型之间的指令遵循能力差异,还对大模型的未来研究提供了宝贵的参考依据。
魔搭社区:https://www.modelscope.cn/datasets/ADoubLEN/Meeseeks
GitHub: https://github.com/ADoublLEN/Meeseeks
Huggingface:https://huggingface.co/datasets/meituan/Meeseeks

